Monitoring und Service-Historie
Das letzte Tutorial von Track D: die org-weite Betreibersicht auf den laufenden Betrieb — was läuft, was lief, wer hat was ausgeführt, wo häufen sich Fehler und was muss weg.
Worum es hier geht
Wir betreiben die Muster GmbH als Org-Admin. Der Helpdesk-Assistent (aus Track C) läuft im Chat, ein E-Mail-Kategorisierungs-Service läuft als geplanter Intervallplan — und einzelne Läufe scheitern. Du überwachst org-weit, prüfst den Intervallplan-Bestand, analysierst Fehler und richtest eine Aufräum-Routine ein.
Voraussetzung: Rolle Organisations-Administrator oder höher — Intervallpläne fremder Nutzer und die vollständige Historie sind erst ab dieser Rolle sichtbar. C5/C6 zeigten den Einzelfall-Drill-down; D5 hebt das auf Organisationsebene: alle Ausführungen, alle Nutzer, alle Pläne, mit Filtern, Auditing und Housekeeping.
runningservices.html, servicehistory.html …) und Spaltennamen können je Version abweichen — sie sind hier als Beispiel mit „gegen Instanz prüfen“ gekennzeichnet.Quellen und Stand
Geprüft gegen das AuxData-Administrator-Handbuch (Stand Juni 2026). Hinweis: Im aktuellen Juni-Handbuch sind Monitoring und Service-Historie nicht mehr als eigenes Kapitel geführt (das frühere Kapitel ist jetzt die Public REST API). Die Ansichten (runningservices.html, finishedservices.html) existieren weiter in der Instanz — gegen Instanz prüfen. Belegbar bleiben die Inhalte über das Benutzerhandbuch (Kap. 5.2/5.3 laufende und beendete Services, Kap. 7.3 Intervallplan-Übersicht) sowie das Admin-Handbuch (Kap. 6.1 Service-Typen, Kap. 4.10 Dokumentenlebenszyklus inkl. FINISHED_ERROR); Querverweise auf Kap. 13 (Verbrauch/Kosten, vgl. D3) und Kap. 11 (Feedback als Symptomquelle, vgl. C6). Mini-Quiz mit 6 Fragen, kein Zertifikat.
Was läuft gerade
Die org-weite Live-Sicht auf laufende und beendete Services.
1Laufende Services live
Die Seite runningservices.html zeigt alle aktuell aktiven Ausführungen der Organisation — Aktualisierung alle 5 Sekunden. (Admin-HB · Monitoring)
Spalten: ID, Agent-Name, Service-Name, Zeitstempel, Fortschritt, Status und ein Details-Button. Der Button öffnet die Ausführungs-Ansicht mit Eingabe-Parametern, Zwischenergebnissen je Workflow-Schritt, finalem Output, Fehlermeldungen/Stack-Traces und Token-Verbrauch je Schritt. (Seiten-URL und die numerische Status-Zuordnung gegen Instanz prüfen — im Juni-Handbuch belegt sind die Klartext-Status „In Arbeit", „Eingabe erforderlich", „Mit Fehlern beendet", „Fertig" und „Abgebrochen".)
2Beendete Services & Statuscodes
finishedservices.html ist dieselbe Tabelle, zeigt aber nur die Status 0, 2 und −2 — filterbar nach Tagen (Standard: 7). Ideal für die Frage „Wie viele Ausführungen sind in den letzten 24 Stunden gescheitert?“ (Admin-HB · Monitoring)
- −2
- Vom Benutzer abgebrochen.
- 0
- Abgeschlossen.
- 1
- In Arbeit.
- 2
- Mit Fehlern beendet.
- 3
- Fertig, noch nicht angeschaut.
- 5
- Wartet auf Benutzereingabe (Feedback-Schritt).
✓ Das hast du geprüft
Vollständige Service-Historie mit Filtern
Die org-weite Ausführungs-Spur für Auditing, Troubleshooting und Verbrauch.
1Reiter „Service-Historie“
Die Seite servicehistory.html ist die detaillierte organisationsweite Übersicht mit allen Ausführungen — weiter zurückreichend als die beendeten Services. (Admin-HB · Monitoring)
2Drei typische Anwendungen
- Auditing
- Nachweis, wer welchen Service wann aufgerufen hat.
- Troubleshooting
- Fehlerhäufigkeit pro Service erkennen.
- Verbrauch
- Token-Accounting je Ausführung.
✓ Das hast du geprüft
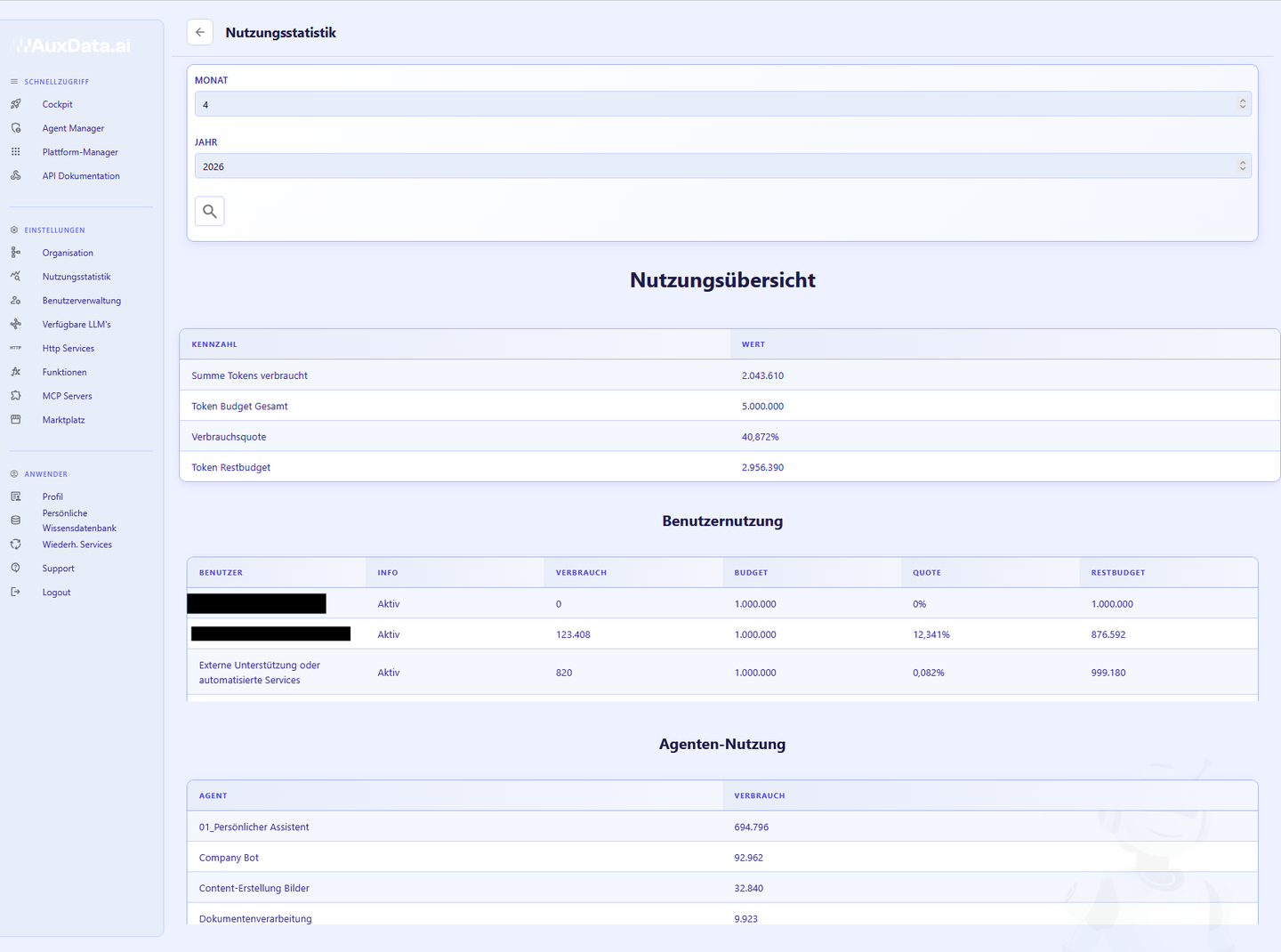
Organisations-Intervallpläne
Alle geplanten Läufe der Organisation — unabhängig vom Ersteller.
1Die Intervallplan-Tabelle
Die Seite serviceintervalllistorganisation.html listet alle geplanten, wiederkehrenden Ausführungen der Organisation — egal, wer sie angelegt hat. (Admin-HB · Monitoring, 14.5)
Pro Zeile: ID, Anwender (Ersteller), Agent, Service, Nächste Ausführung, Intervalltyp (Minuten/Stunden/Tage/Monate), Intervall und ein Aktiv-Häkchen. Laut 14.5 ist es dieselbe Seite, die Endbenutzer im Cockpit aufrufen — als Admin darfst du hier auch fremde Pläne bearbeiten, sofern deine Rolle ≥ Organisations-Administrator ist.
2Offboarding-Risiko
✓ Das hast du geprüft
Fehleranalyse
Vom Symptom bis zur Ursache — und wieder zurück zum grünen Lauf.
1Lebenszyklus eines Laufs
Jede Ausführung durchläuft denselben Lebenszyklus — die Fehleranalyse setzt genau da an, wo es klemmt. (Admin-HB · Monitoring)
2Der Fehleranalyse-Workflow (7 Schritte)
- Symptom beobachten — Benutzerfeedback mit 1–2 Sternen, eingehende Sentry-Alerts oder ein Anstieg auf
/metrics. - Details öffnen — in
runningservices.html/finishedservices.htmldie Zeile klicken →cockpitaiserviceexecution.html. - Schritt identifizieren — welcher Workflow-Schritt ist fehlgeschlagen?
- Prompt & Parameter lesen — stimmen Quality Gate, Chunk-Limit, Persona?
- Korrektur — im Workflow-Schritt-Editor anpassen (vgl. Kap. 6 / Track C).
- Nachtest — den Service im Cockpit selbst testen.
- Dokumentation — den Fix in der Commit-Message bzw. im Changelog des Agent-Exports vermerken.
✓ Das hast du geprüft
Aufräumen & Wartung
Die Plattform schlank halten — aber erst Aufbewahrung prüfen.
1Housekeeping-Routine
Langfristig lohnt eine wiederkehrende Wartungs-Routine. (Admin-HB · Monitoring)
- Alte Ausführungen
- älter als 12 Monate per API löschen, wenn keine Aufbewahrungspflicht besteht.
- Inaktive Benutzer
- deaktivieren (nicht löschen), so bleibt die Historie auswertbar.
- Veraltete Pläne
- Intervallpläne ausgeschiedener Nutzer erst deaktivieren, letzte Ausführungen prüfen und dann übernehmen, anpassen oder löschen (knüpft an Stufe 3 an).
- Fehler-Dokumente
- in der Wissensdatenbank Dokumente mit Status FINISHED_ERROR untersuchen und neu chunken oder löschen.
2Erst prüfen, dann löschen
Hinweis: Das Löschen alter Ausführungen läuft laut Quelle primär per API, nicht als UI-Button — Verfügbarkeit und Endpunkt gegen die Instanz prüfen.
✓ Das hast du geprüft
Betriebs-Rhythmus & Track-D-Abschluss
Aus Einzelseiten wird eine Routine — und Track D ist komplett.
1Monitoring-Betriebs-Rhythmus
Ein fester Rhythmus macht aus den Einzelseiten eine verlässliche Betriebs-Routine. (Admin-HB · Monitoring)
- Täglich
- beendete Services / Fehlerquote der letzten 24 h prüfen (
finishedservices.html, Status 2). - Wöchentlich
- Intervallplan-Bestand und Token-Trends durchsehen.
- Bei Offboarding
- die Org-Intervallpläne abklopfen.
- Monatlich / quartalsweise
- Housekeeping fahren und Aufbewahrung prüfen.
Orientierung gibt die Seitenübersicht aus 14.8 mit Zielgruppen: runningservices/finishedservices (Ops), servicehistory (Audit), serviceintervalllistorganisation (Admin), organisationusage/getusage (Controlling) — plus Feedback- und DSGVO-Seiten als Nachbarn.
2Track D — geschafft
Du hast die Muster GmbH verwaltbar gemacht:
- D1
- Rollen, Gruppen und Rechte.
- D2
- Organisation und Microsoft-Konnektor.
- D3
- Modelle und Token-Budgets steuern.
- D4
- DSGVO, Anonymisierung und Audit.
- D5
- Monitoring und Service-Historie.
Damit ist die Muster GmbH rechtssicher eingerichtet, kostenkontrolliert und betriebsüberwacht — der Kreis aus Gestalten (Track C) und Verwalten (Track D) ist geschlossen.
Track D abgeschlossen!
Das org-weite Monitoring steht: laufende und beendete Services, vollständige Historie für Audit und Troubleshooting, Intervallplan-Bestand inklusive Offboarding-Risiken, systematische Fehleranalyse und eine Housekeeping-Routine. Mach das Quiz und geh dann weiter zu E1 — Public REST API & Token-Authentifizierung. Eine Lernbestätigung gibt es später über den Track-Kompetenzcheck, nicht hier im Tutorial.
✓ Das hast du geprüft
Sitzt das Monitoring?
6 Szenariofragen aus den Stufen 1–6. Kein Zertifikat — zur Selbstkontrolle. Beliebig oft wiederholbar.