Wissensdatenbanken pflegen
In C1 hast du den Agenten angelegt. Jetzt befüllst, optimierst und diagnostizierst du seine Wissensdatenbank — bis die Antworten sitzen.
Was du in diesem Tutorial tust
Wir befüllen den Container „Produkthandbücher" des Helpdesk-Assistenten, prüfen die Container-Strategie, stellen das Chunking richtig ein und tunen die Suche über die Knowledge-Base-Diagnose. Bau-Modus: echte Reiter und Felder als Konfigurations-Mockups, plus die Verarbeitungskette als Animation.
Voraussetzung: C1 (Agent und Start-Container angelegt). Worum es konzeptuell geht, erklärt B3 — hier geht es ums Pflegen und Tunen.
Quellen und Stand
Geprüft gegen das AuxData-Administrator-Handbuch (Stand Juni 2026), Kapitel 4 (Wissensdatenbank), 3.5/3.7 (Chunking) und 12.6 (LightRAG-Datenschutz) sowie das Schritt-Tutorial 17.
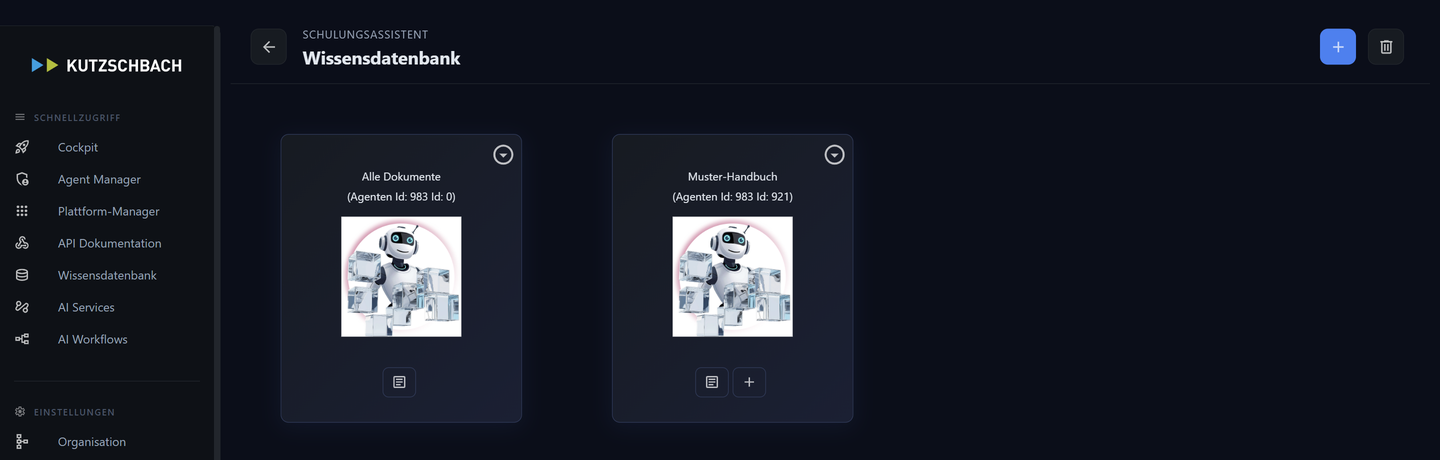
Container-Strategie
Wissen sinnvoll trennen.
1Container als Ordnungsprinzip
Ein Container ist eine logische Sammlung mit eigenem Bereich in der Vektor-Datenbank; er zählt Dokumente und Chunks separat. (AH 4.1)
Trenne nach Thema (HR, IT, Produkt), Zeit (Archiv 2024, Aktuell 2026) oder Projekt. Pro Agent sind beliebig viele Container möglich; Rechte steuerst du am Agenten, nicht über Dokument-Tags. (AH 4.1; AH 2.7; Tut 17 S4.1)
- Produkthandbücher
- unser Start-Container für den Helpdesk-Assistenten.
- FAQ
- kurze Frage-Antwort-Paare (anderes Chunking, siehe Stufe 4).
- Release-Notes
- zeitlich getrennt, regelmäßig erneuert.
2Strategie festlegen
✓ Das hast du jetzt erledigt
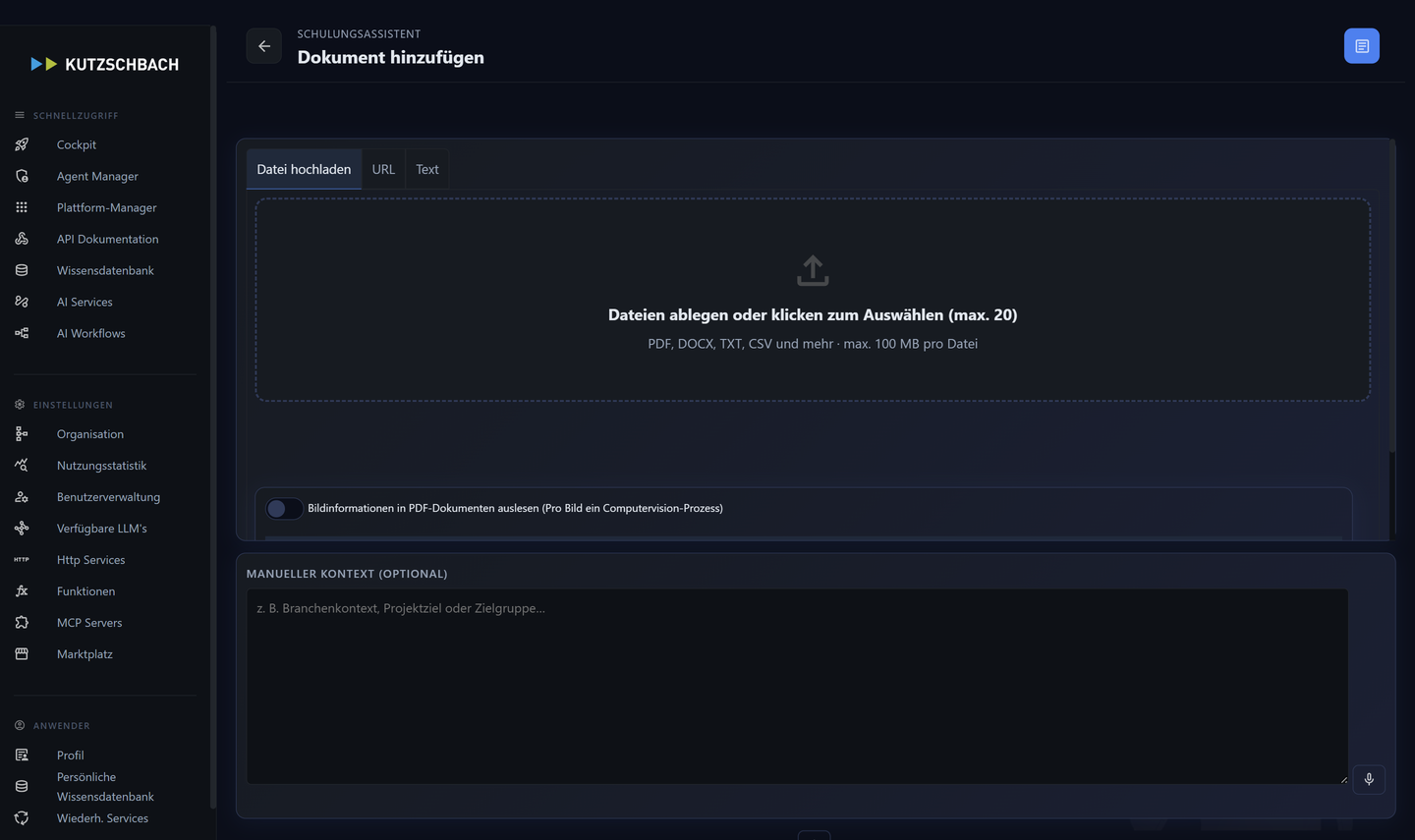
Dokumente hochladen
Drei Wege ins Wissen.
1Datei, URL oder Text
Der Upload-Dialog hat drei Reiter. (AH 4.2; AH 4.5)
- Datei hochladen
- PDF, DOCX, ODT, TXT, HTML, XLSX, CSV, JSON, RTF, MP4/WAV/MP3, Bilder.
- URL (Web-Crawler)
- Startadresse + Tiefe + max. Seitenzahl; jede Seite wird ein Dokument. Begrenzungen schützen vor ausufernden Crawls.
- Text direkt
- Titel + Inhalt für punktuelle Ergänzungen.
✓ Das hast du jetzt erledigt
Verarbeitung & Status
Was nach dem Upload passiert.
1Die Verarbeitungskette
Nach dem Hochladen läuft eine asynchrone Kette — Anreicherung und LightRAG nur, wenn aktiviert. (AH 4.2)
2Status in der Dokumentenliste
- PROCESSING_CHUNKING
- wird in Chunks zerlegt.
- PROCESSING_CONTEXTENRICHMENT
- Kontext-Anreicherung läuft.
- PROCESSING_CHUNKPROCESSING
- Embeddings werden berechnet.
- PROCESSING_LIGHTRAG
- Wissensgraph wird aufgebaut.
- FINISHED_SUCCESSFUL
- einsatzbereit — ab jetzt suchbar.
- FINISHED_ERROR
- Fehler — Meldung im Detail.
Quelle: AH 4.3.
3Pro-Dokument-Aktionen
In der Dokumentenliste kannst du Chunks einsehen, neu chunken, Analyseergebnisse öffnen oder Dokumente löschen. Beim Löschen verschwinden Dokument, Chunks und Vektoren; LightRAG-Einträge werden im Lebenszyklus mitgedacht. (AH 4.3, 4.10)
FINISHED_ERROR — wo schaust du nach der Ursache?✓ Das hast du jetzt erledigt
Chunking richtig einstellen
Die richtige Größe je Dokumenttyp.
1Chunk-Größe nach Dokumenttyp
Die Chunk-Größe entscheidet über Präzision vs. Zusammenhang. AH nennt 1000 Zeichen als Startwert und 1000–2000 als typischen Bereich; kleinere oder größere Werte sind Praxisheuristiken, die du testen solltest. (AH 3.5/3.7; Tut 17 S2.1)
- Klein (500–800)
- präzise Fakten, FAQ, kurze Q&A.
- Mittel (1000–1500)
- ausgewogen — guter Standard.
- Groß (2000+)
- zusammenhängende Texte, Erzählung.
✓ Das hast du jetzt erledigt
Such-Diagnose & Quality-Gate-Tuning
Sehen, was die Suche findet — und nachregeln.
1Knowledge-Base-Suche als Diagnose
Gib einen Suchbegriff ein und sieh, welche Treffer mit welchem Score (in %) zurückkommen. (AH 4.4)
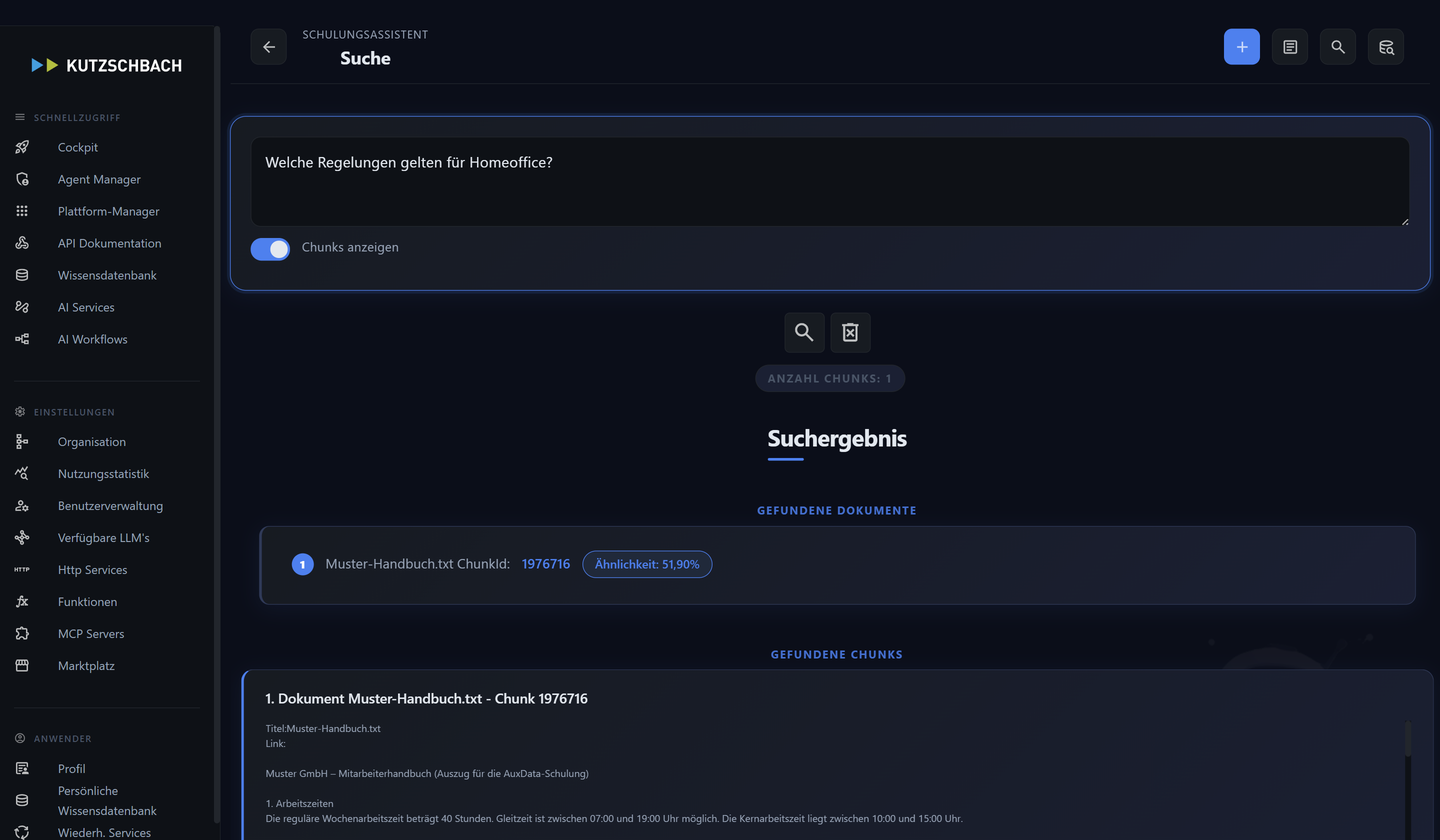
- Produkthandbuch_v3.pdf
- Score 86 % · 4 Chunks — entspricht 0,86 und liegt oberhalb eines Gates von 0,60.
- Schnellstart.pdf
- Score 61 % · 2 Chunks.
- Altes_Handbuch_2019.pdf
- Score 37 % — unter dem Quality Gate, verworfen.
2Die Stellschrauben
✓ Das hast du jetzt erledigt
LightRAG-Entitäten pflegen
Den Wissensgraph sauber halten.
1Was LightRAG erzeugt
Bei aktivem LightRAG extrahiert ein LLM pro Chunk Entitäten (Personen, Organisationen, Orte, Konzepte) und Relationen — ein Wissensgraph neben der Vektor-DB. (AH 4.7)
Die Entitäten-Ansicht zeigt je Eintrag Name, Beschreibung, Relevanz-Score und verknüpfte Relationen.
2Pflege für bessere Qualität
- Aliase vergeben
- „M. Mustermann" = „Max Mustermann" zusammenführen.
- Falsch-Entitäten löschen
- versehentlich extrahierte Treffer entfernen.
✓ Das hast du jetzt erledigt
Qualitätssicherung & Wartung
Dauerhaft gute Antworten.
1Testen
Lege Testfragen an und prüfe die Antworten gegen die Quellen; nutze Suche/Abfrageanalyse für Score-Diagnose und behalte Performance und Token-Kosten im Blick. (AH 4.6, 4.8; Tut 17 S5)
2Dokumentlebenszyklus
- Quelldokument aktualisiert → Neu chunken bzw. erneuter Upload über dieselbe Dokument-ID.
- Dokument obsolet → Löschen entfernt Dokument, Chunks, Vektoren und Graph-Einträge.
- Veraltete oder doppelte Dokumente regelmäßig bereinigen.
Quelle: AH 4.10.
Wissensdatenbank gepflegt!
Container befüllt, Chunking eingestellt, Suche getunt, Entitäten gepflegt und ein Wartungsrhythmus gesetzt. Mach das Quiz und geh dann weiter zu C3 — AI-Services und Parameter definieren.
✓ Das hast du jetzt erledigt
Sitzt das Pflegen?
7 Szenariofragen aus den Stufen 1–7. Kein Zertifikat — zur Selbstkontrolle. Beliebig oft wiederholbar.