Wie AuxData Wissen findet
Container, Chunking, Embedding, Quality Gate und LightRAG — wie aus deinen Dokumenten recherchierbare Antworten werden. Für Power-User und Entscheider.
Worum es geht
Im wissensgestützten Betrieb beantwortet AuxData Fragen nicht einfach aus dem Bauch des Sprachmodells, sondern holt zur Anfrage passende Stellen aus deinen Dokumenten. Wenn Wissensdatenbank-Container eingebunden sind, durchsucht der Agent sie zur Laufzeit, wählt passende Textstellen aus und gibt sie dem Modell als Kontext. Dieses Prinzip heißt RAG (Retrieval-Augmented Generation). Dieses Tutorial zeigt die einzelnen Stationen und ihre Stellschrauben.
Wir bleiben in der Muster GmbH beim Helpdesk-Assistenten mit dem Container „Produkthandbücher". Es geht ums Verstehen, nicht ums Einstellen — das Pflegen der Wissensdatenbank zeigt Track C.
Quellen und Stand
Inhaltlich geprüft gegen das AuxData-Administrator-Handbuch (Stand Juni 2026), insbesondere Kapitel 3.5 (Reiter Wissensdatenbank / Chunking) und Kapitel 4 (Wissensdatenbank administrieren, Knowledge-Base-Suche, LightRAG).
Track B ist konzeptlastig: Statt Klickstrecken erklären wir die Plattform-Logik. Schematische Darstellungen veranschaulichen die Konzepte.
Die RAG-Pipeline
Von der Frage zur belegten Antwort.
1Der Agent lernt deine Dokumente nicht auswendig
Das Sprachmodell hat deine internen Dokumente nicht automatisch im Training.
Stattdessen durchsucht der Agent bei wissensgestützten Antworten seine Wissensdatenbank, wählt die passendsten Textstellen aus und gibt sie dem Modell als Kontext mit. Das Modell formuliert die Antwort dann auf Basis dieser gefundenen Stellen — deshalb kann AuxData Quellen anzeigen. Dieses Prinzip heißt Retrieval-Augmented Generation (RAG). (AH 4)
2Sechs Stationen
Vom hochgeladenen Dokument bis zur Antwort sind es sechs Schritte.
- Dokument — in einen Container hochgeladen.
- Chunking — das Dokument wird in Textabschnitte zerlegt.
- Embedding — jeder Chunk wird in einen Bedeutungs-Vektor übersetzt.
- Suche — die Frage wird mit den Vektoren verglichen.
- Quellen — die besten Treffer werden ausgewählt (Quality Gate, Limit).
- Antwort — das Modell formuliert aus diesen Quellen. (AH 4.2, 3.5)
✓ Das solltest du jetzt können
Container & Chunking
Wissen ordnen und in durchsuchbare Häppchen zerlegen.
1Container — das Ordnungsprinzip
Ein Container ist eine logische Sammlung innerhalb der Wissensdatenbank eines Agenten.
Bei der Anlage bekommt er automatisch einen eigenen Bereich in der Vektor-Datenbank und zählt Dokumente und Chunks separat. Container trennen nach Thema (HR, IT-Sicherheit, Produktdaten), Zeit (Archiv 2024, Aktuell 2026) oder Projekt. (AH 4.1)
2Chunking — Dokumente in Abschnitte
Beim Upload zerlegt AuxData jedes Dokument in Chunks (Textabschnitte).
Die Chunk-Größe liegt typisch bei 1000–2000 Zeichen: kleinere Chunks ergeben präzisere Treffer, aber mehr Vektoren. Rolling Chunks sorgen für eine Überlappung von rund 10 % zwischen aufeinanderfolgenden Chunks, damit kein Satz an der Schnittkante seinen Zusammenhang verliert. (AH 3.5)
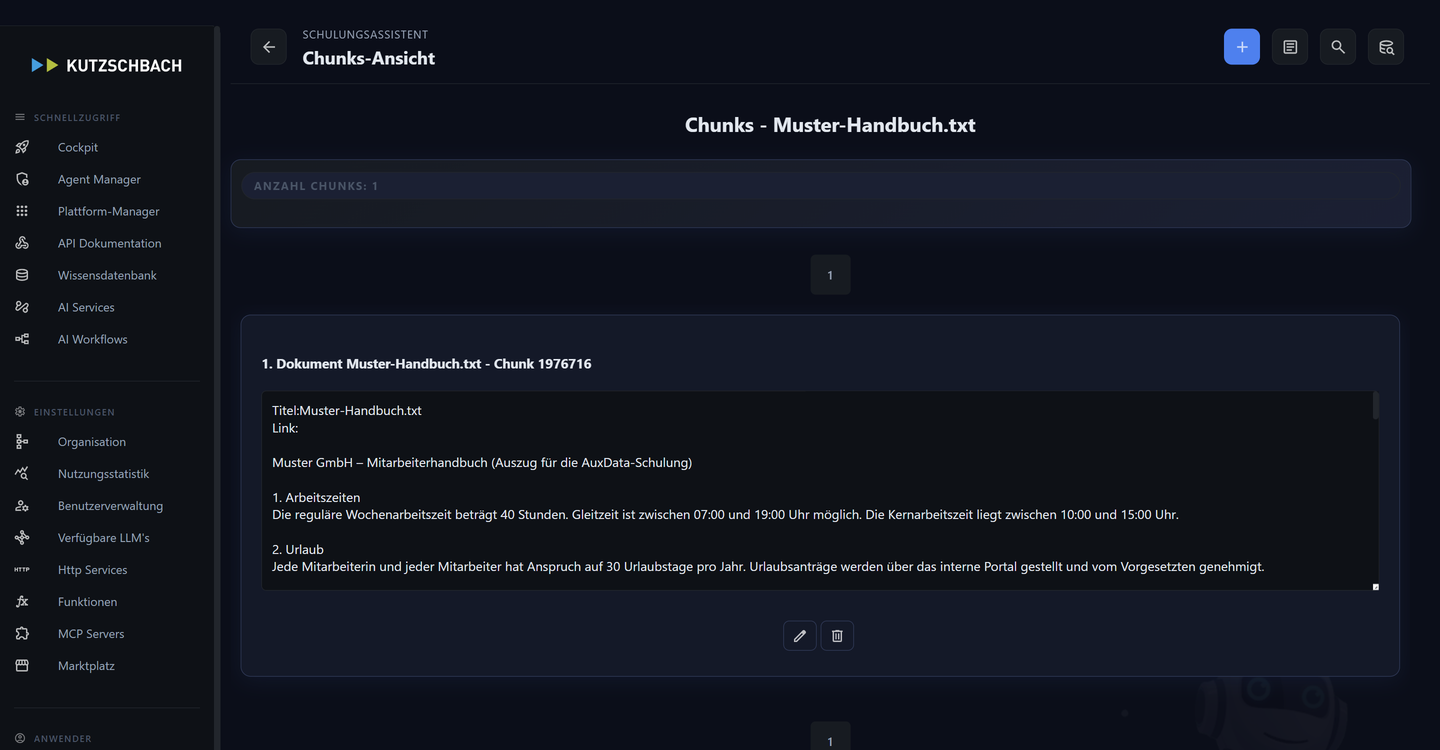
3Was beim Upload passiert
Die Verarbeitung läuft asynchron in einer festen Kette: Chunking → (optional) Kontext-Anreicherung → Embedding-Berechnung → (optional) LightRAG → Speicherung (in MySQL und der Vektor-Datenbank pgvector). Den Fortschritt zeigt der Dokumentstatus an — von PROCESSING_CHUNKING über Zwischenstände wie PROCESSING_CHUNKPROCESSING bis FINISHED_SUCCESSFUL (ab dann ist das Dokument suchbar). (AH 4.2, 4.3)
- Chunk-Größe
- Startwert 1000 Zeichen.
- Rolling Chunks
- aktiv (Standard-Empfehlung).
Praxis-Richtwerte aus AH 3.7.
✓ Das solltest du jetzt können
Kontext-Anreicherung
Chunks verständlicher machen — und was das kostet.
1Das Problem mit isolierten Chunks
Ein einzelner Chunk kann ohne seine Umgebung mehrdeutig sein.
Steht in einem Abschnitt nur „Das Gerät startet danach neu", ist unklar, welches Gerät und nach was. Solche Chunks werden bei der Suche schlechter gefunden, weil ihnen der einordnende Kontext fehlt.
2Zwei Wege, Kontext zu ergänzen
AuxData kann Chunks beim Verarbeiten zusätzlichen Kontext mitgeben:
- Kontext-Anreicherung
- Ein LLM ergänzt pro Chunk automatisch einen einordnenden Kontext-Satz. Das erhöht den Recall, kostet aber zusätzliche Tokens. (AH 3.5)
- Manueller Kontext
- Ein Freitext, den du beim Upload vergibst und der jedem Chunk als Metadatum mitgegeben wird — z. B. „Interne Richtlinie der Abteilung Einkauf". (AH 4.2)
3Wann lohnt sich das?
✓ Das solltest du jetzt können
Embedding & semantische Suche
Nach Bedeutung suchen, nicht nach Wortlaut.
1Embedding — Bedeutung als Vektor
Jeder Chunk wird in einen Vektor übersetzt — eine Zahlenfolge, die seine Bedeutung repräsentiert.
Diese Vektoren liegen in der Vektor-Datenbank pgvector. Ähnliche Bedeutungen ergeben benachbarte Vektoren. (AH 4.2)
2Semantische Suche
Auch die Frage wird eingebettet — und mit den Chunk-Vektoren verglichen.
Gesucht wird nach Nähe im Vektorraum, also nach Bedeutung statt nach exaktem Stichwort. Deshalb findet eine Frage nach „freien Tagen" auch den Abschnitt „Urlaubsanspruch", obwohl kein Wort übereinstimmt. (AH 4.4)
- Stichwortsuche
- findet nur, was wortwörtlich vorkommt.
- Semantische Suche
- findet, was dasselbe meint — auch mit anderen Worten.
3Tiefer suchen, wenn nötig
✓ Das solltest du jetzt können
Quality Gate & Chunk-Limit
Wie viel und wie gut ins Modell kommt.
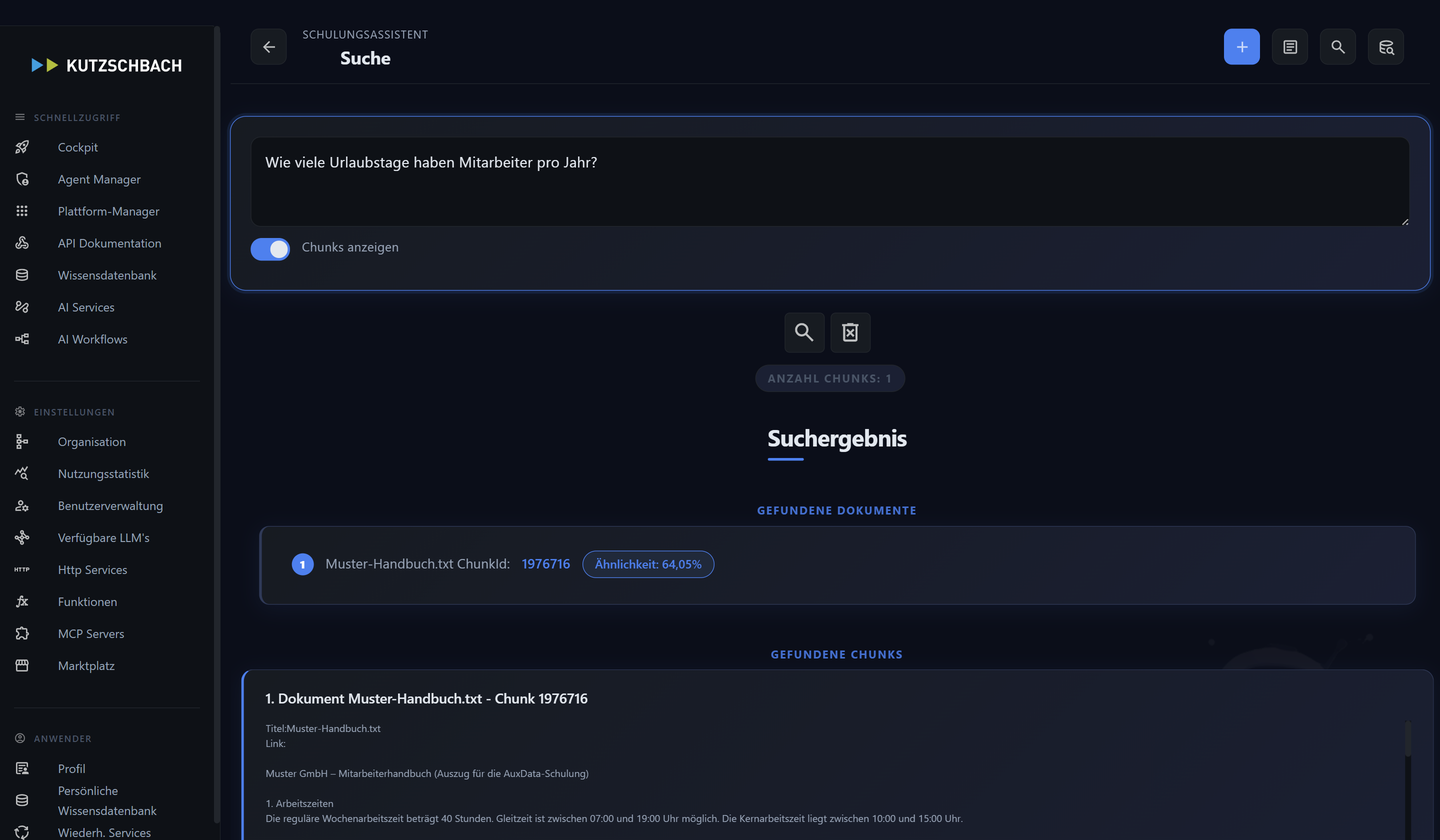
1Quality Gate — die Relevanz-Schwelle
Das Quality Gate ist ein Schwellenwert für die Relevanz eines Chunks.
Je nach Oberfläche begegnet dir derselbe Gedanke unterschiedlich: im Agent-Editor als Dezimalwert von 0–1, in Diagnoseansichten als Score in Prozent und im Workflow-Schritt als Wert von 0–100. Gemeint ist immer die Mindestähnlichkeit, ab der ein Treffer in den Kontext darf. (AH 3.2, 4.4, 4.6, 6.3)
Treffer mit einem Score unterhalb der Schwelle werden verworfen — sie kommen gar nicht erst ins Modell. Ein hohes Gate liefert nur sehr passende Stellen (wenig Rauschen, aber Gefahr von Lücken); ein niedriges Gate lässt mehr durch. (AH 3.2)
2Chunk-Limit — wie viele Stellen
Das Chunk-Limit begrenzt, wie viele Chunks pro Anfrage in den Modell-Kontext aufgenommen werden.
- Quality Gate
- Startbereich ca. 0.45–0.70 bzw. 45–70 in Prozentdarstellung.
- Chunk-Limit (Chatbot)
- 8–15.
- Chunk-Limit (AI-Service)
- 10–30.
Praxis-Richtwerte aus AH 3.2 und 3.7.
3Die Stellschrauben in der Praxis
Mit der Knowledge-Base-Suche im Admin-Bereich sieht man, welche Chunks mit welchem Score (in Prozent) zurückkommen — ideal, um Embeddings und Gate zu beurteilen. Faustregel: Kommt eine bekannte Antwort nicht zurück, das Chunk-Limit erhöhen oder das Quality Gate senken. (AH 4.4, 4.6)
✓ Das solltest du jetzt können
LightRAG & Roadmap
Der optionale Wissensgraph — und wie es weitergeht.
1LightRAG — Wissen als Graph
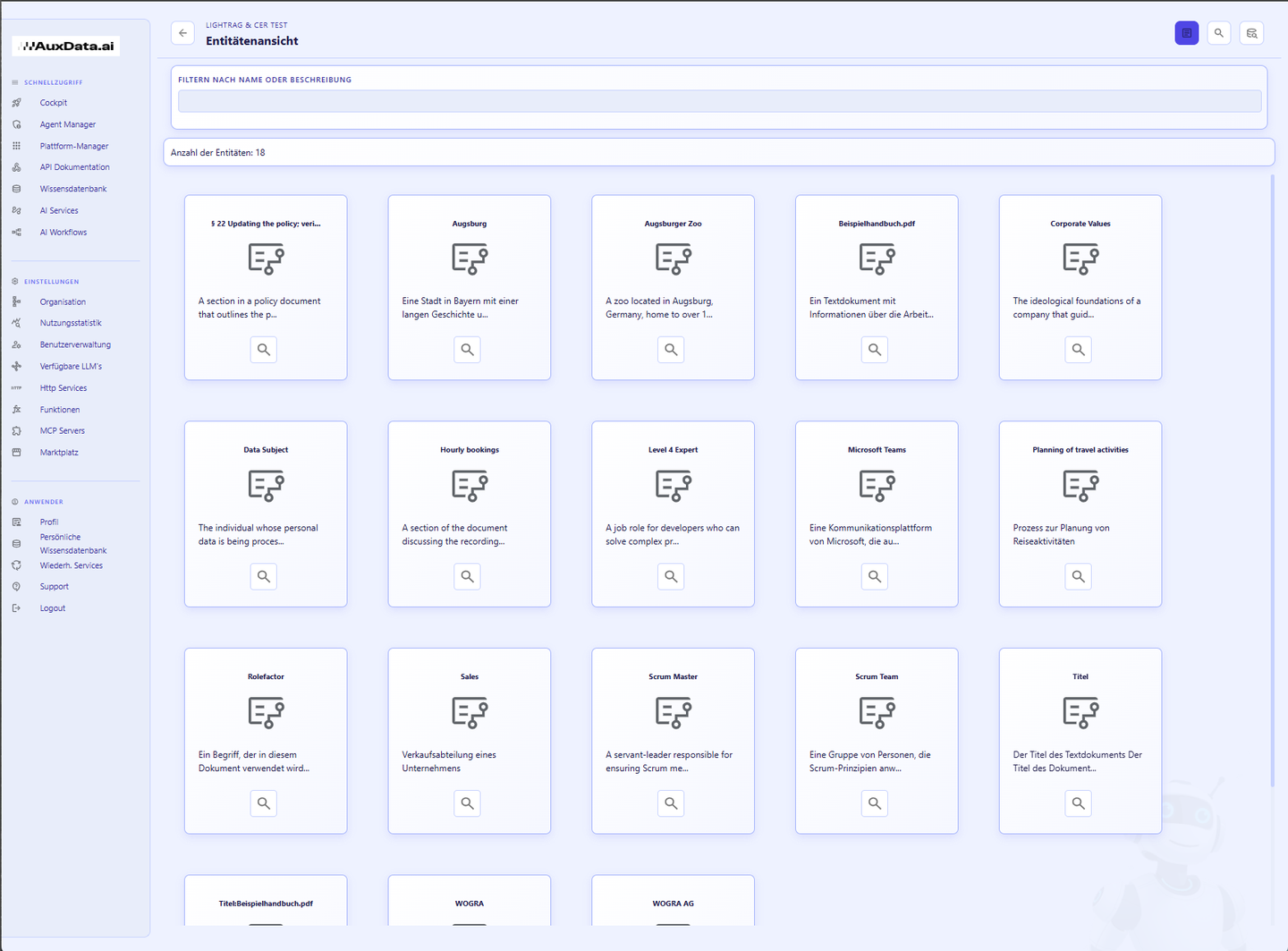
Ist die Option LightRAG aktiv, entsteht beim Upload zusätzlich ein Wissensgraph.
Ein LLM analysiert jeden Chunk auf benannte Entitäten (Personen, Organisationen, Orte, Konzepte) und deren Beziehungen. Das Ergebnis wird neben der Vektor-Datenbank gespeichert und ermöglicht graph-basiertes Retrieval — also Antworten, die Zusammenhänge über mehrere Dokumente hinweg nutzen. (AH 4.7)
2Pflege & Kosten
In der Entitäten-Ansicht lassen sich Entitäten ansehen, mit Aliasen versehen oder löschen, um die Graph-Qualität zu verbessern. Der Preis: LightRAG bedeutet 1–3 zusätzliche LLM-Aufrufe pro Chunk (Entitäten, Relationen, Embedding der Entität). Deshalb ist es standardmäßig aus und wird gezielt für graph-basierte Analysen aktiviert. (AH 4.7, 4.8, 3.7)
3Wie es weitergeht
- Hier in B3
- verstanden, wie AuxData Wissen findet.
- Track C2
- Wissensdatenbanken pflegen: Container anlegen, Dokumente hochladen, Chunking einstellen.
- B4
- Modelle, Token und DSGVO-Stufen — auch die Kostenseite von Anreicherung und LightRAG.
- Track D4
- Datenschutz von LightRAG, Lösch-Checkliste und Audit.
✓ Das solltest du jetzt können
Du weißt jetzt, wie AuxData Wissen findet!
Dokument → Chunking → (Kontext) → Embedding → semantische Suche → Quality Gate & Limit → Antwort — optional ergänzt um den LightRAG-Wissensgraph. Mach das Quiz und geh dann weiter zu B4 — Modelle, Token und DSGVO-Stufen.
Sitzt die Wissenssuche?
6 Fragen aus den Stufen 1–6. Kein Zertifikat — einfach zur Selbstkontrolle. Beliebig oft wiederholbar.